
When working on any distributed system, you might need to write data into different sources and guarantee that there is still consistency across all systems. Focusing on authorization, if you have your authorization system completely separated from your application, let’s say you’re using something like Auth0 FGA, you could end up with an inconsistent state where, in your primary application, you could have updated the user’s access to a specific resource, for example, but it hasn’t yet been updated in your authorization system, so what can you do to avoid this issue?
To try Auth0 FGA,
sign up hereIn this blog post, you’ll explore the dual-write problem in the context of authorization and learn about different strategies for mitigating it.
Keep in mind that Auth0 FGA is Auth0’s highly available and scalable solution built on top of OpenFGA. This blog post might refer to OpenFGA specifically, but you can extrapolate that into your Auth0 FGA instance.
What is the Dual-Write problem?
Let’s start by talking about distributed systems. A distributed system is one in which a collection of components communicate with each other only by passing messages, and they appear to their users as a single coherent system. This leads to a few characteristics, such as concurrency of components, meaning different parts of your system can perform tasks at the same time, or independent failure of components, where different parts of the system could fail and recover without affecting other components.
The dual-write problem comes when you need to write data to multiple systems atomically. Because you’re dealing with a distributed system, you can’t use atomic transactions, so if one write fails, the other system can be left in an inconsistent state. Imagine a user making an order online, and they need to update their address. The system needs to update both the user database and the shipment service - if either fails, the shipment will not go where the user expected it to be.
Another example of leaving your system in an inconsistent state is when writing to a database and publishing an event to RabbitMQ, so it propagates through other systems. What if publishing the event fails? You’ll get an inconsistency between your database state and your events, and now you have yourself a dual-write problem.
Note that the dual-write problem doesn’t only happen when writing to a database and emitting events; it is one of the most common scenarios. This problem can occur anytime you’re trying to write to two (or more) separate systems or when dealing with asynchronous operations where having a single transaction with a rollback is not feasible.
In the context of authorization, even if your application is a monolith, you’ve decided to use an authorization system like OpenFGA, you could also run into this problem. Let’s say you completely delegate authorization decisions to OpenFGA, but also keep a copy of the data in your application. Writing data in one place or the other might fail, and then one of your systems would be inconsistent with the other.
For example, imagine you have a system where you want a user to be the editor of a document, and you store this information in your database. You need to tell OpenFGA that this user has an editor relationship with the document. Something could go wrong while updating the relation in OpenFGA. For example, there could be a network issue, and OpenFGA might never be updated. This will cause your application to end up in an inconsistent state, where your application knows the user is an editor of the document. Still, OpenFGA doesn’t know about this relationship, so if another part of your application checks against OpenFGA, you will get a different result than expected. In this case, you can’t simply roll back because the error could have happened at any stage, and traditional database transactions don’t work in these types of systems, as they are entirely independent of each other.
To understand how to mitigate the dual-write problem, let’s consider a piece of the example above:
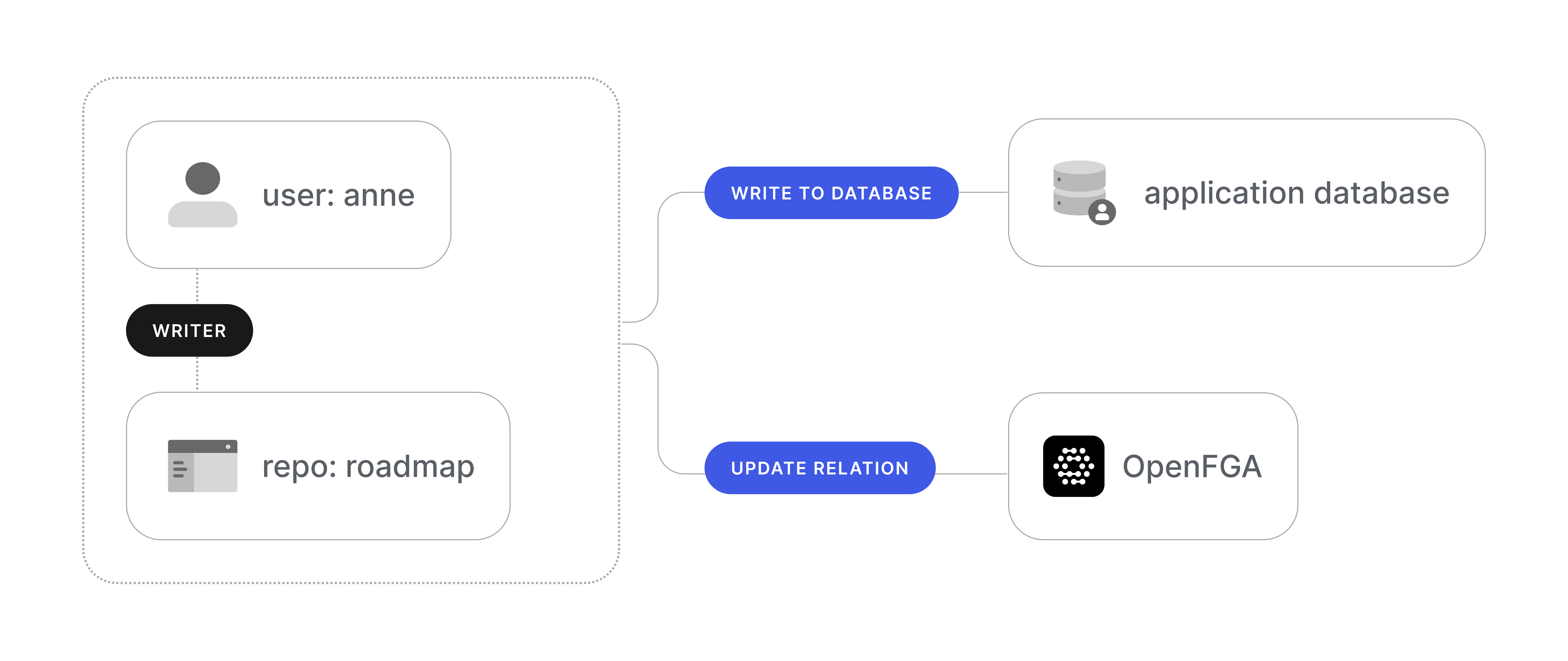
You have an application where you need to update the access of user:anne to repo:roadmap and make them a writer. You have an application with a local database, and you’re using OpenFGA for authorization; in an ideal world, both of these data sources would get updated, and everything will work perfectly, but we already know this is not the case.
Keeping the example above in mind, how can you keep both your local database and OpenFGA in a consistent state? Here are some strategies:
Strategy 1: Sequential Dual-Write
With a sequential dual-write approach, the application writes data first in your application’s database and then in OpenFGA (or vice versa). If one write fails, you can have error handling mechanisms to roll back the other write or retry the failed write operation and avoid the dual-write problem.
A sequential dual-write approach would work as follows:
- Write data to the local database.
a. If the write was successful, update the relation tuple in OpenFGA.
b. If the write fails, show an error message. - Write to OpenFGA
a. If the write is successful, both writes were successful, and the sequence ends.
b. If the write fails, we need to roll back and delete the record on the local database to keep consistency and show a message that there was an error.
Pros
- Simplicity: Sequential writes are straightforward to understand.
- Isolation of Errors: If an OpenFGA write fails, database writes are unaffected, and vice versa.
Cons
- No Atomicity: If one write fails, you may have inconsistent states between the database and OpenFGA, so you must cover all possible error scenarios.
- Higher Latency: Waiting for one write before initiating the second increases latency.
- Rolling back can be difficult or impossible: if the service has to do many things before writing to OpenFGA. The error can happen at any point in the process, for example, with an unexpected crash in the server, there won’t be an easy way of rolling back.
Strategy 2: Transactional Outbox
Another common strategy to mitigate the dual-write problem is the transactional outbox pattern, which relies on database transactions to update two tables: the table your app wants to update and an outbox table. The idea is to use atomic database transactions to ensure the write is successful in the two tables of your database. Once the write is successful, you can use a separate process to consume it from the outbox table and update any other service.
If you think about your application and OpenFGA, you’d have a transaction created only in the database of your application, along with an entry in an outbox table that indicates an event requiring a write to OpenFGA. For example, you could have a messaging streaming broker like RabbitMQ to propagate the event to OpenFGA.
Going back to the example where you have an application where you need to update the access for user:anne to repo:roadmap and make them a writer and update OpenFGA, a transactional outbox approach would work as follows:
The application has multiple tables, including the repo and the outbox.
- Write data to the local database in a single transaction: update the table outbox to indicate there’s a new unprocessed event, and table repo to indicate the new relation in this example
- Your outbox service checks the outbox table every X amount of time, when there’s a new record found, and updates the relation in OpenFGA.
a. Mark the record as processed in the outbox table if the write was successful.
b. If the write fails, you could have a retry mechanism or wait for the next processing time since the record wasn’t marked as processed yet.
Pros
- Atomicity: The primary database and outbox entry are written in the same transaction, ensuring that data is either fully written or not at all.
- Asynchronous Execution: OpenFGA writes can happen in the background, reducing latency for the main database operation.
- Recovery: If there’s an error, you can retry the operation by checking the outbox table for unprocessed records.
Cons
- Eventual Consistency: OpenFGA may have a slight delay in syncing.
- Outbox Table Management: Additional maintenance is required for the outbox table, including periodic cleanups.
Strategy 3: Event Sourcing
In an event-driven approach, every time an object is updated, the event-sourced system will translate that into an event. In the case of using OpenFGA, you could use event-streaming with Apache Kafka, for example, and have a consumer service to read from it.
Think of the example of an application where you need to update the access of user:anne to repo:roadmap and make them a writer.
To mitigate the dual-write problem using an event-sourcing approach, you would do the following:
- Publish the event regarding
user:anneis now awriterofrepo:roadmapto a streaming platform - The consumer service can then consume the event and update the relation in OpenFGA
a. If it fails, the consumer manages retries for failed writes to ensure that changes are eventually applied to OpenFGA.
Pros
- Decoupling: The application logic is simplified as a consumer service consumes directly from the source
- Scalability: Suitable for high-throughput applications as the stream of events and OpenFGA writes are independent.
Cons
- Eventual Consistency: There will be a delay until the message is processed and applied to OpenFGA.
- Error Handling: Retries and dead-letter queues must be carefully managed to handle failures gracefully.
Strategy 4: Change Data Capture
Another approach to mitigate the dual-write problem is Change Data Capture (CDC), which refers to the process of tracking any change in the database (change) so that it can be captured and propagated into another system almost in real-time (captured). An example implementation of CDC is Debezium, an open-source distributed platform that captures row-level changes in your application’s database to see and respond to those changes.
In the context of OpenFGA, using CDC can offer almost real-time updates, allowing real-time consistency between your permissions and your application. CDC is beneficial when your system can tolerate minor delays.
In the example of updating the permission for user:anne to be a writer of repo:roadmap, let’s assume you’re using a SQL database, when data is changed, let’s say by inserting a new record (note: you can listen to INSERT, UPDATE or DELETE triggers) the following happens when using a CDC approach:
- The CDC Listener Service connects to the SQL database and listens for notifications on the table
- When a notification is received, it’s processed, and the relation is updated in OpenFGA
a. If successful, you can log a success message
b. If a failure, you can implement a retry mechanism
There are multiple ways to implement CDC. The approach above is trigger-based, but generally, approaches can be push or pull depending on which entity updates the other. This means the source database pushes the updates to OpenFGA, or OpenFGA polls the source database every X amount of time to pull the updated data. The example above represents a push approach.
Pros
- Real-Time Changes: CDC can provide near real-time updates to OpenFGA.
- Minimal Impact on App Logic: CDC operates at the database level, so the application remains unaffected other than the listening service to the database.
Cons
- Complexity: CDC requires a more complex setup and monitoring, especially in managing failed events.
- Eventual Consistency: There can be a slight lag before updates are reflected in OpenFGA.
Strategy 5: Durable Execution Environments
A Durable Execution Environment is a system designed to make sure that the execution of code or a workflow finishes to completion, by persisting the application state at every step and automatically retrying execution after a failure. These systems use the concept of durable functions, which can persist in a state outside of the function execution context (hence the name) so that, in case of failure, it can be resumed from the point of failure. Examples of durable execution environments are Temporal or Dapr.
In our example, we want to update the relation user:anne and make them a writer for repo:roadmap. You have a durable workflow that assigns tasks to available workers who are in charge of updating OpenFGA. A durable execution environment approach would look as follows:
- Write into the local database and log the event to the durable workflow
- The durable workflow assigns the task to the first available worker to attempt to update the relation in OpenFGA
a. The worker will report back to the durable workflow, whether it was a success or failure, in which case it will retry the task
Pros
- Fault Tolerance: The system is more resilient to failures, ensuring that partial updates don’t lead to inconsistencies. Durable execution ensures that work is not duplicated on failure; it can resume from where it left off without reprocessing state.
Cons
- Complexity: Defining and managing durable transactions can be challenging.
- Latency: Durable transactions add to the latency and complexity of handling failures.
Conclusion
Overall, the dual-write problem might present itself in a distributed architecture, and there are different ways to mitigate it. In this blog post, you learned about five different strategies, their pros and cons, and gained an understanding of which one could best suit your use case.
It really depends on the user case you have and how comfortable you are with the latency between your systems. Most of the downsides mentioned for each strategy are really inherent to distributed systems, and there is no silver bullet to solve distributed transactions; all approaches have their trade-offs and requirements. In the case of authorization, it is tightly coupled into your application’s logic, and moving it into a different service could offer significant advantages in the long run, but it also requires careful architectural planning and implementation.
Here’s a summary of each strategy with the key benefits and main drawbacks:

About the author

Carla Urrea Stabile
Senior Developer Advocate
I've been working as a software engineer since 2014, particularly as a backend engineer and doing system design. I consider myself a language-agnostic developer but if I had to choose, I like to work with Ruby and Python.
After realizing how fun it was to create content and share experiences with the developer community I made the switch to Developer Advocacy. I like to learn and work with new technologies.
When I'm not coding or creating content you could probably find me going on a bike ride, hiking, or just hanging out with my dog, Dasha.